




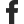
Serverless data lake using AWS
The power of Data in determining operational agility and enterprise business value cannot be overlooked. Analytics performed over data sources acquired from click-streams, social media, internet-connected devices, and log files provide fast integration to improve time to insights, business growth, production boost, customer retention, and taking the right calls at the right time.
A serverless data lake is a popular system of storing and analyzing data in a single repository and features autonomous maintenance and architectural flexibility for diverse kinds of data. The purpose of the Data Lake is the democratization of access to Data across the organization.
Enterprises are now migrating to the public cloud for creating Data Lakes on platforms, particularly AWS. Some of the reasons include cost optimization, zero requirement of operational maintenance, large and cheap storage, faster time to market, competent serverless components on AWS, DR and BCP availability, faster scalability, better security, and much more.
An architecture for a cloud-native, serverless data lake using AWS native resources like S3, Athena, and Glue.
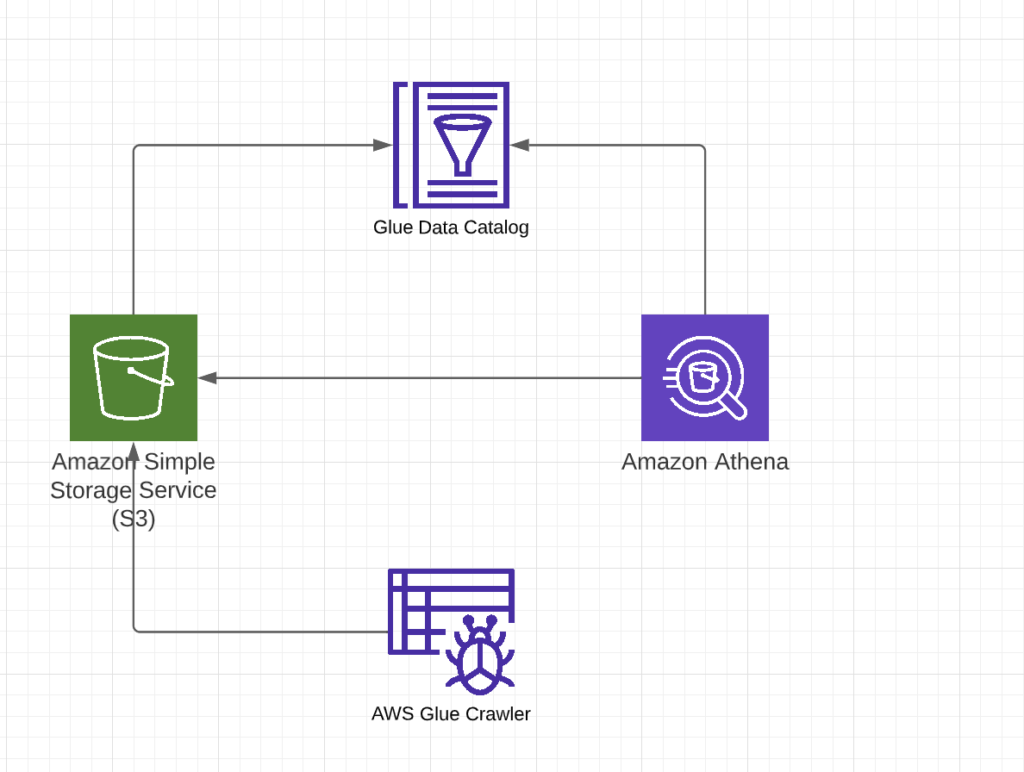
Steps to create a quick data lake in AWS is as follows,
Create an S3 bucket to store the data,
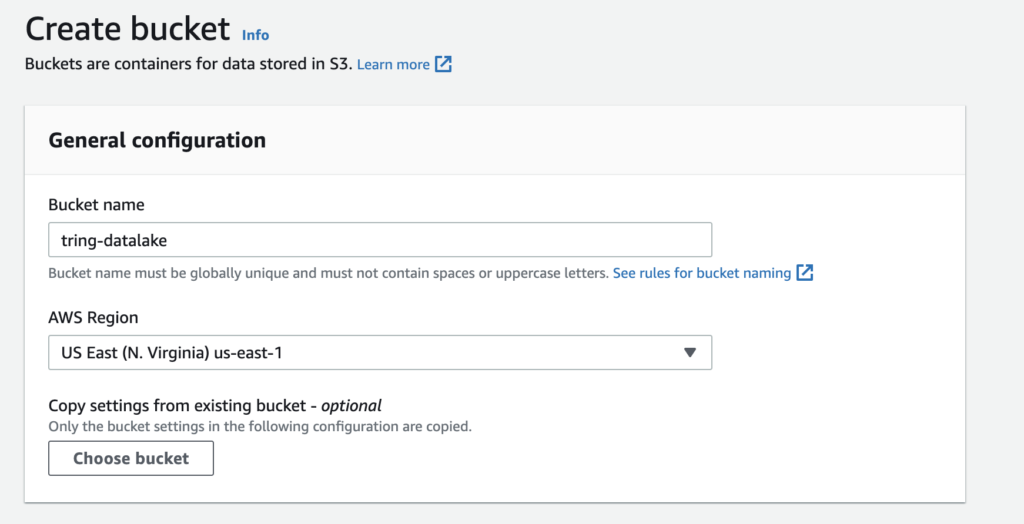
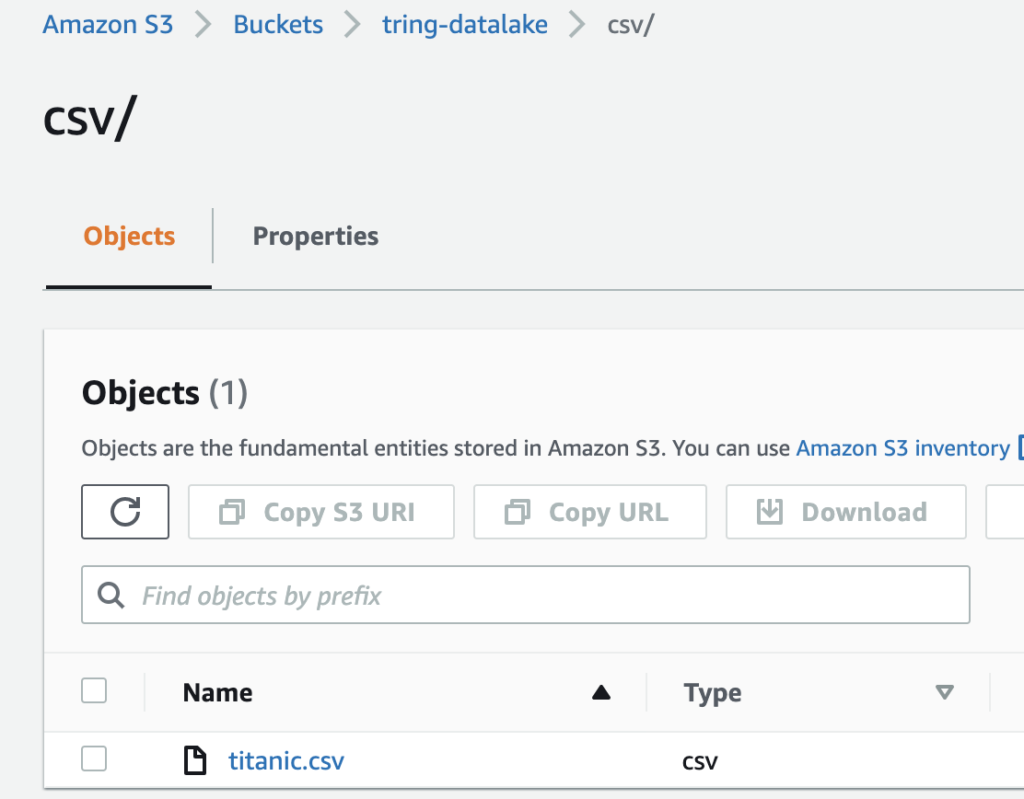
Let’s try to query a sample data set which is currently in CSV format,
Create a new folder called CSV and upload the CSV to that folder in the S3 bucket that was created earlier.
AWS Glue is a serverless data integration service that makes it easy to discover, prepare, and combine data for analytics, machine learning, and application development.
We will use AWS Glue to crawl the data to form the schema.
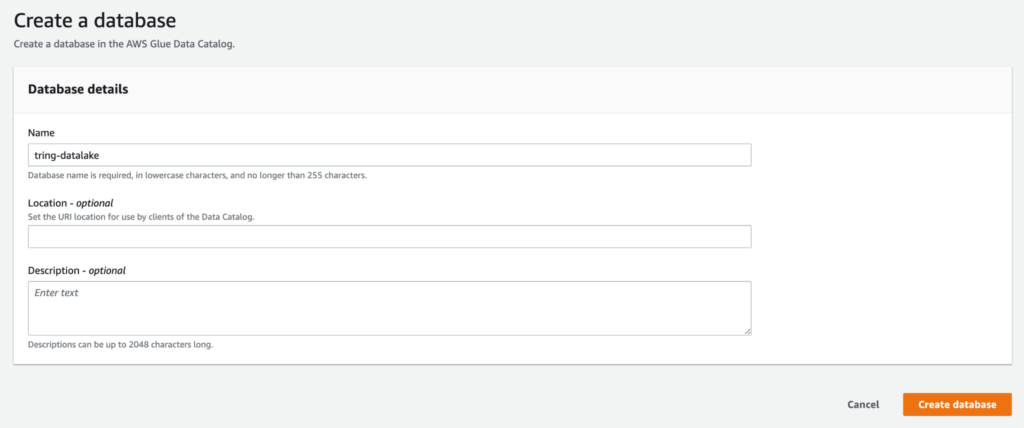
First, let’s add a new database.

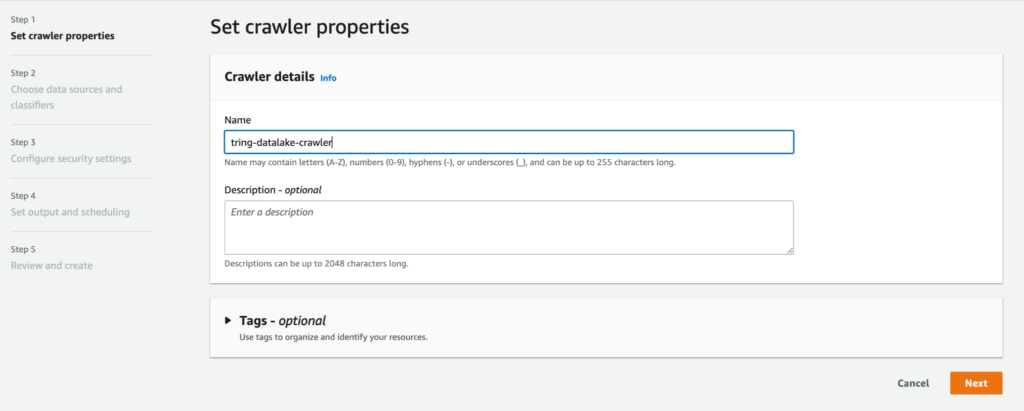
Create a new crawler and use it to crawl the data that is stored in S3.
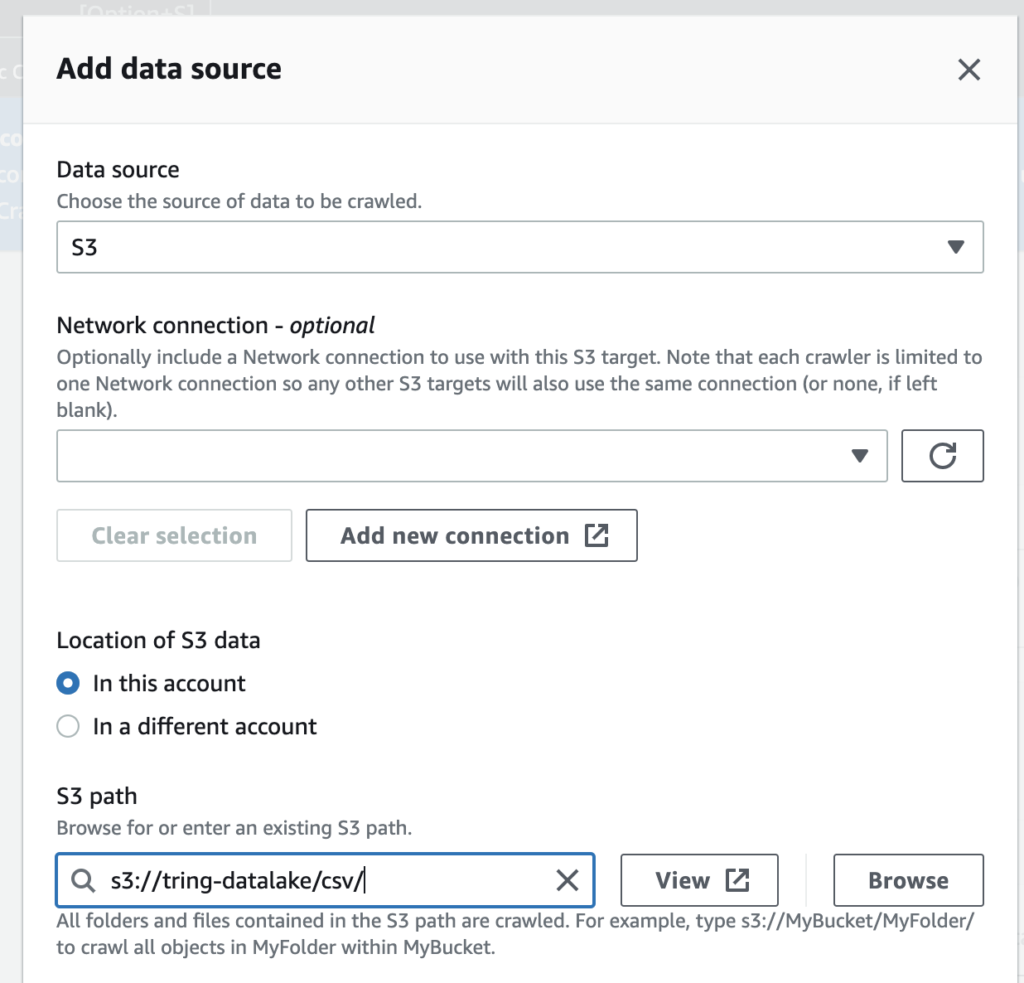
Add the S3 bucket as a source,
Create an IAM role to have permissions to crawl the S3 data,
Select the database which was created earlier,
Click on Review and Create.
Now once the crawler is created, click on “Run” to run the crawler,
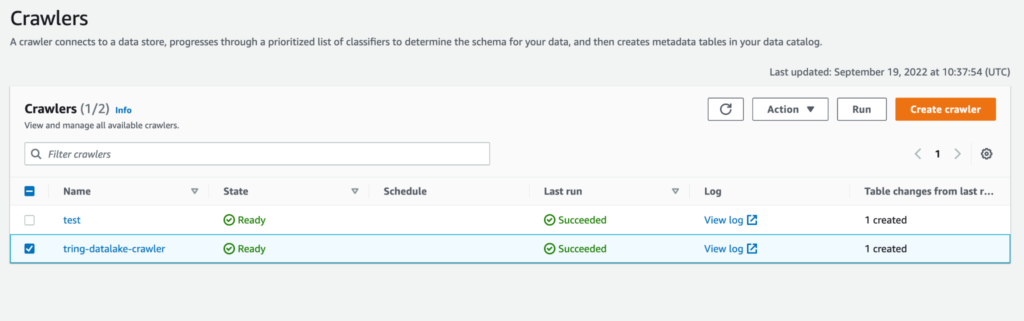
Once the crawler has run, it will let us know the number of tables created,
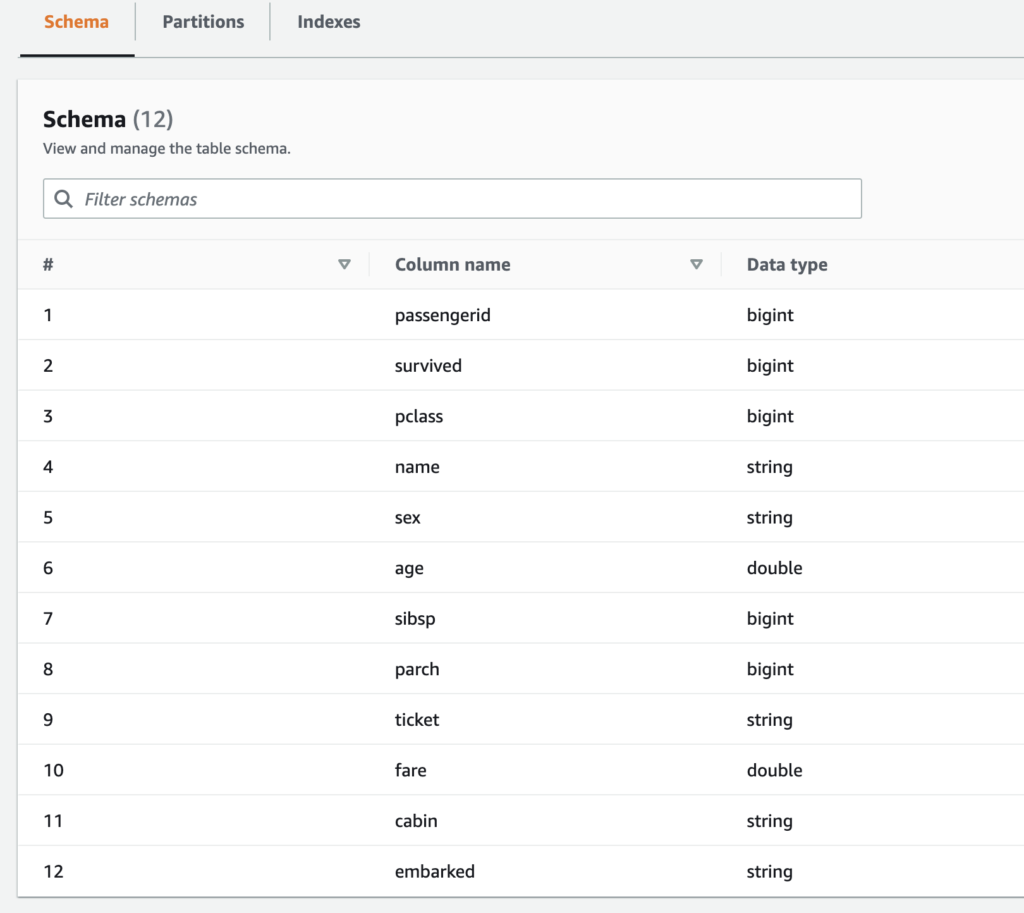
Check the schema of the table that was created,
Amazon Athena is an interactive query service that makes it easy to analyze data in Amazon S3 using standard SQL. Athena is serverless, so there is no infrastructure to manage, and you pay only for the queries that you run.
We will use Amazon Athena to query the data in S3,
Inside , set the query location

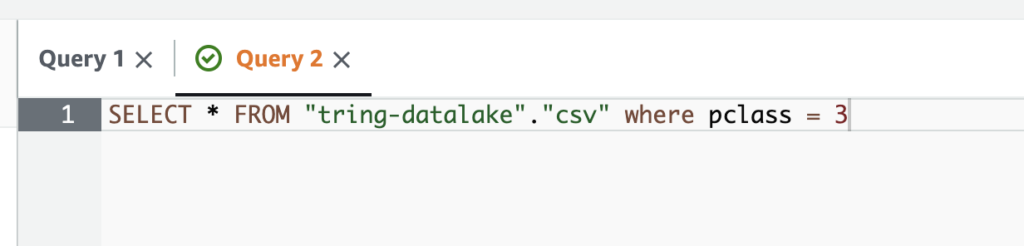
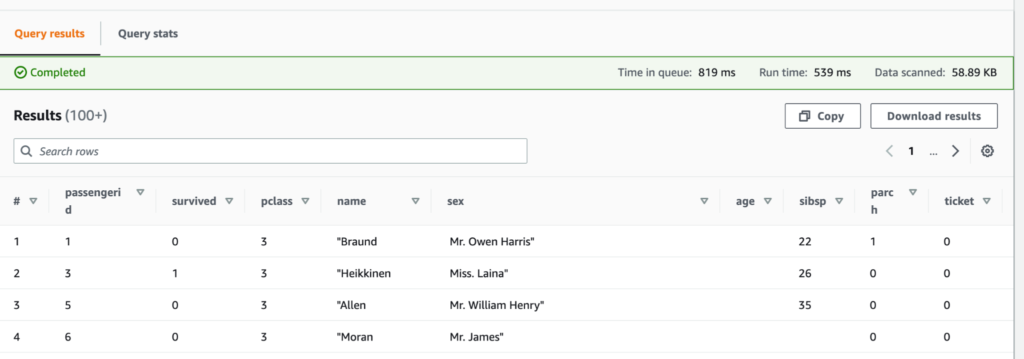
Using Athena – we can query the data inside S3 using standard SQL like below,
To adapt and succeed, a technologically advanced organization must take advantage of every opportunity available to it. Today, no organization can afford to ignore the massive amount of Data at its disposal. A data lake provides unparalleled flexibility for unlocking data’s analytics potential.
Related Post













































