




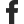
The future is Data Lakehouse and you need to embrace it.
In recent years, we have witnessed the emergence of a new data management architecture that evolved independently across numerous clients and use cases- data lakehouse. In this blog, we depict this novel data management architecture and its benefits over the traditional methods.
Introduction: Data Warehouse, Data Lake and Data Lakehouse
Business intelligence applications have traditionally used data warehouses an information storage architecture ideal for structured data. Data warehouse technology has evolved since its introduction in the late 1980s and MPP architectures have led to systems that can manage larger volumes of data. With the dawn of the Big Data era, businesses began to unlock the value of working with unstructured data, semi-structured data, and data with high variety, velocity, and volume. Unfortunately, a number of these use cases didn’t fit well with the data warehouse model and its structured and ordered way of information storage.
With businesses gathering more and more data from a variety of sources, architects began to imagine a single system that could contain data for a variety of analytic products and workloads. A decade ago, companies started establishing data lakes, where unstructured information is stored in its raw format. While data lakes are hugely powerful and flexible architectures enabling enterprises to capture all their data in every format and not just relational data, they lack some key features: they don’t support transactions; they don’t enforce data quality; and their lack of consistency makes it nearly impossible to mix appends and reads, and batch and streaming jobs. Furthermore, there is a lack of robust governance and privacy protection, and the data layout might not be organized for performance. As a result of these limitations, many of the promises of data lakes have not materialized.
The need for a flexible, high-performance system is constantly increasing, as many recent AI advancements have been better models to process unstructured data (text, photos, video, and audio). However, these are the types of data that a data warehouse is not designed to handle. The typical solution is to use several systems, such as a data lake, multiple data warehouses, and other specialized systems like streaming, time-series, graph, and picture databases. But having a variety of systems adds complexity and, more crucially, delay, because data professionals must frequently move or copy data across systems. To overcome these problems, enterprises working with large and varied data sets have developed a new approach: a hybrid architecture called the data lakehouse.
What is Data Lakehouse Architecture?
Enterprise software company, Databricks uses the portmanteau “lakehouse” in their paper (Lakehouse: A New Generation of Open Platforms that Unify Data Warehousing and Advanced Analytics), which argues that the data warehouse architecture will wither in the coming years and be replaced by a new architecture called the lakehouse. Instead of the two-tier data lake + relational data warehouse model, you will just need a data lakehouse, which is made possible by implementing data warehousing functionality over open data lake file formats.
A data lakehouse, as the name proposes, is a unified platform for data storage new, open data architecture that merges a data warehouse and data lake into a single whole, with the purpose of addressing each one’s limitations. In brief, the lakehouse system uses low-cost storage to keep enormous volumes of information in raw formats very much like data lakes. ‘At the same time, it brings structure to data and empowers data management features like data warehouses by implementing the metadata layer on top of the store. This allows various teams to utilize a single system to get all the enterprise data for a scope of projects, including data science, machine learning, and business insights. Unlike data warehouses, the lakehouse architecture can store and process loads of varied data at a lower cost, and unlike data lakes, that information can be managed and optimized for SQL performance.
A lakehouse is a new, open architecture that combines the best elements of data lakes and data warehouses. Lakeshouses are enabled by a new open and standardized system design: implementing similar data structures and data management features to those in a data warehouse, directly on the kind of low cost storage used for data lakes
Key features of Lakehouse
As a combination of the components of data warehouses and data lakes, data lake house feature elements of both data platforms. The key features of data lakehouse are:
- Simultaneous reading and writing of data: In an enterprise lakehouse, numerous data pipelines will frequently be reading and writing information simultaneously. Support for ACID exchanges guarantees consistency as multiple parties simultaneously read or compose data, regularly utilizing SQL.
- Schema support with data governance mechanisms: With the lakehouse architecture, clients will be able to control the schema of their tables thanks to the support of schema enforcement (to prevent the accidental transfer of garbage information) and evolution (to empower automatic adding of new columns). The system is also loaded with data governance features including access control and reviewing.
- Direct access to source data: Lakehouse architectures enable using BI tools directly on the source information. This decreases staleness, lessens latency, and eliminates the expense of having to operationalize two copies of the information in a data lake and in a warehouse.
- Compute resources decoupled from storage: This means storage and computing use discrete clusters. Consequently, these systems can scale to more simultaneous users and larger data sizes. This property is also possessed by some modern data warehouses.
- Standardized storage formats: The storage formats used by lakehouses are open and standardized (such as Parquet) and lakehouses provide an API, so a variety of tools and engines, including AI and Python/R libraries, can proficiently access the data directly.
- Support for diverse data types: The lakehouse architecture can be used to store, refine, analyze, and access data types needed for many new information applications, including images, video, audio, semi-structured data, and text.
- Support for diverse workloads: including data science, machine learning, and SQL and analytics. Different tools may be expected to support different workloads, but they all rely on the same data repository.
- End-to-end streaming: Real-time reports are the standard in many enterprises. Support for streaming wipes out the requirement for separate systems committed to serving real-time data applications.
Advantages of Data Lakehouse
Data warehouses aren’t optimized for unstructured information types making it necessary to concurrently manage multiple systems: a data lake, numerous data warehouses, and different specialized structures. Maintaining numerous structures is a costly affair and can even impair your capacity to access timely data insights.
A single data lakehouse has numerous advantages over a multiple-solution system, including:
- Reduced data redundancy: Because of the advantages of the data warehouse and the data lake, most companies opt for a hybrid solution. However, this approach often leads to data duplication, which can be costly. Data lakehouses reduce data duplication by providing a single all-purpose data storage platform to cater to all business data demands.
- Cost-effective data storage: Data lakehouses leverage the cost-effective storage features of data lakes by utilizing low-cost object storage options. They also reduce the expense of maintaining multiple data storage systems by providing a single solution.
- Support for a wider variety of workloads and formats: Data lakehouses enable advanced data analytics by providing direct access for some of the most widely used business intelligence tools (Tableau, PowerBI). Additionally, data lakehouses use open-data formats with APIs and machine learning libraries, including Python/R, making it easy for data scientists and machine learning engineers to utilize the data.
- Simplified schema and data governance: Data lakehouse architecture enforces schema and data integrity making it easier to implement robust data security and governance mechanisms.
Disadvantages of Data Lakehouse
In Spite of all the buzz around lakehouse, it’s worth remembering that the concept is still nascent. Below are some drawbacks to be considered before committing to data lakehouse architecture:
- Most enterprises already use data warehouses. The time and cost to migrate and implement data lakehouse from warehouses need to be justified by its benefits.
- Modularity and decoupling are proven architectural principles that seem incompatible with the concept of a single monolithic platform. One-size-fits-all designs may offer decreased functionality compared to those designed for specific use cases.
- The lakehouse model has been questioned by critics. Some argue that a hybrid, two-tier architecture featuring a data lake and a data warehouse can be just as effective as a lakehouse, when combined with the right automation tools.
- The lakehouse concept relies upon the use of cutting-edge technology, so the limitations of current and legacy tech may prevent fulfillment of lakehouse’s full potential.
- The tools to enable data lakehouse are in their infancy. At this early stage, they don’t have all the features and functions needed to live up to the hype. They may be ready for early adopters, but the more cautious architects may take a wait-and-see approach.
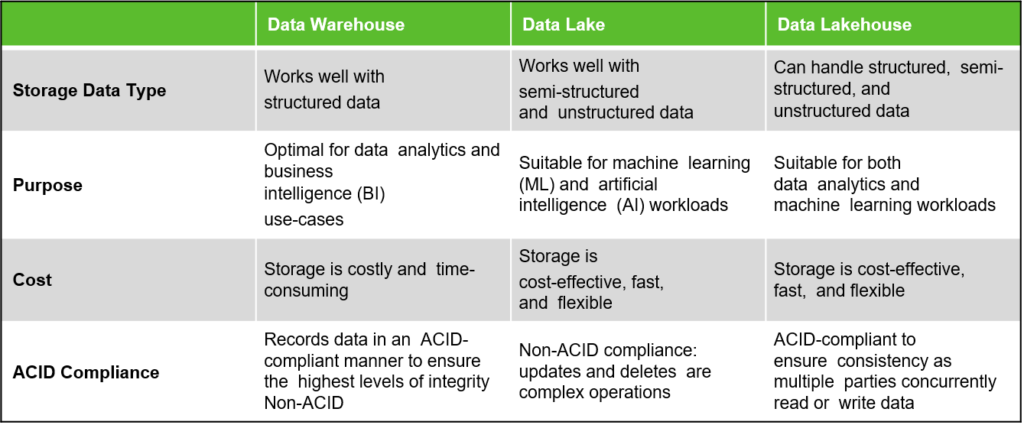
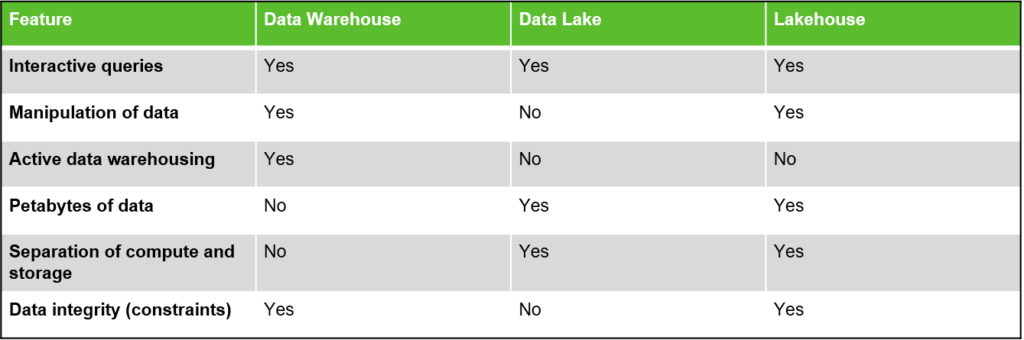
Best of Both Worlds? Data Warehouse v/s Data Lake v/s Lakehouse
Conclusion
In the future, the data warehouse architecture we know today is likely to be replaced by the innovative lakehouse approach, which will offer open direct-access data formats, support for machine learning and data science, superior performance, and lower costs.
But despite the benefits, enterprise organizations are not expected to immediately embrace lakehouse architecture and abandon their investments in Amazon Redshift, Google BigQuery, Microsoft Azure, Data Lake or Snowflake.
Still, the lakehouse ecosystem is growing and many vendors seem to be heading in that direction. The Databricks Lakehouse Platform, and Microsoft’s Azure Synapse Analytics service, (which integrates with Azure Databricks) already use the lakehouse approach. Other services such as BigQuery and Redshift Spectrum have some of the lakehouse features listed above, though they are models that focus primarily on BI and other SQL applications. Companies who want to construct their own lakehouse storage systems have access to open source file formats (Delta Lake, Apache Iceberg, Apache Hudi) that are suitable for the purpose.
Hopefully, after reading this blog post, you have a better understanding of how data lakehouse architecture is changing the way we store and manage Big Data, unlocking new capabilities and improved efficiencies that will increase performance and reduce cost. Put it all together and one thing becomes clear: lakehouse is here to stay!
Related Post













































